The Art and Science of Code Obfuscation
obfuscation SecurityEngineering
Introduction
Recently, I had the opportunity to deliver a lecture at MagicLeap on the intriguing topic of code obfuscation—a subject I’m deeply familiar with. This blog post is an extension of that lecture, where I’ll delve into various techniques and strategies employed in code obfuscation, shedding light on how they enhance software security. From my own experiences and insights gained over the years, I’ll explore the intricate blend of artistry and functionality that defines this captivating field.
The Art of Unreadable Code
My first encounter with code obfuscation was back in 2005 during a lecture on coding riddles and puzzles. The lecturer asked the crowd if someone can tell him what the following C code does:

Well, this snippet is from the International Obfuscated C Code Contest (IOCCC). It’s a peculiar competition where participants are tasked with crafting the most convoluted yet functional C code to solve real problems. This particular code calculates an appriximation value of \(\pi\) using Leibniz formula for \(\pi\). Intriguing, right?
It was my initiation into the world of obfuscation, a mind-bending blend of art and code that left me in awe. Fast forward to 2011, where I had the chance to work with NDS on their DRM system. This is where I got my hands dirty implementing obfuscation algorithms and even inventing a few.
Let’s leap to 2023. Participating in the International Obfuscated Python Code Contest (IOPCC), my entry clinched the first-place trophy.
Although this is an artistic example of code obfuscation, in real-world scenarios, these techniques are primarily employed for information security purposes.
Securing Secrets: The Man-At-The-End
Now, imagine you’ve crafted a groundbreaking “Pet Translator” application for Android. Picture this: your app listens to your pet’s sounds and translates them into plain English. It’s revolutionary! You’re eager to share it on Google Play, but there’s a catch – your secret sauce, the algorithm you poured your genius into, needs protection. Enter our main concern: the Man-At-The-End (MATE).
The MATE scenario is when an adversary has all the time and resources in the world to dissect and tamper with your app. It’s static; the code won’t change much, giving the Man-At-The-End the luxury of performing static and dynamic analyses or even tampering with the code. These are the attack vectors we need to counter.
What is Code Obfuscation
So, what is code obfuscation? In simple terms, it’s about making your program more challenging (or “difficult”) for adversaries to understand while retaining its functionality.
Sometimes, people associate code obfuscation solely with techniques for anti-debugging or anti-tampering, but it’s not about that. It’s all about preventing static analysis!
The term “difficult” is intentionally vague because measuring code readability is not an easy task. We rely on others attempting to reverse engineer or understand the code to gauge its difficulty. Typically, this implies that the obfuscated program necessitates more human time, more money, or more computing power to analyze than the original program.
Think of a compiler as a form of obfuscation – it transforms code from one language to another while maintaining functionality (most people will find it hard to understand the compiler’s output).
Compiler optimizations may also be considered as obfuscation - it adds another layer of complexity while preserving functionality. Trying to understand an optimized code could be a difficult and non trivial task.
The connection between obfuscation transformations and compiler optimizations is more than a coincidence - they both change the code while maintaining its functionality but for different purposes.
Evaluating Code Obfuscation
Now, if readability is hard to measure, how do we evaluate code obfuscation? We focus on three key factors:
- Complexity Added: How much does the obfuscation make the code harder to read?
- Resistance to Deobfuscation: How challenging is it for a deobfuscator, a tool designed to reverse the obfuscation process, to break the obfuscation?
- Overheads: What computational or space overheads does the obfuscation introduce to the application?
Every obfuscation (or security layer) has a cost, and the ideal obfuscation minimizes space and runtime overhead while nudging attackers towards dynamic analysis. That’s our goal! We’re aiming to be bulletproof, though it’s impossible(!) - theoretically, every obfuscation is breakable. Making dynamic analysis happen isn’t easy; it requires a different level of effort. Oftentimes, attackers have the code or binary but lack the entire system, preventing execution (think of anything that isn’t PC or mobile). Plus, they often lack the specific toolchain, making compiling the code a challenge. Forcing attackers to abandon static analysis is a significant achievement
Forget About Obscurity
Many people think that obfuscationis all about obscurity, it’s not! A good obfuscation algorithm is one that doesn’t hide anything.
Picture this: I have two bags of sand, one with white sand and the second with black sand. I’m going to mix these two bags together. Now, even if I told you the algorithm behind this operation, the task of separating the sands back into their original bags is pretty challenging. This example illustrates that a strong obfuscation algorithm adds complexity. Even if an attacker knows the obfuscation algorithm, deobfuscating the code remains a formidable challenge.
Obfuscation Building Blocks - Opaque predicates
Now, let’s dive into the realm of transformations, focusing on creating complex expressions.
In this example, we start with a simple expression and aim to expand it into a more intricate one. Think about the following example:
if (var < 100) {
...
}
// Transformed into
if ((var < 100) && ((var - var) * 3 - 1 < 0)) {
...
}
Although it adds complexity it is pretty trivial to understand what is going on, moreover every compiler will optout this expression because it is quite trivial to deduce that this expression yields a constant value (always true).
The catch is that we’re not after just any complexity; we’re in pursuit of something called an opaque predicate—a key element in code obfuscation. Informally, an expression becomes opaque when it possesses properties known to the obfuscator “a priori” but proves challenging for the decipherer to unravel.
To illustrate, let’s examine specific examples involving constructed polynomials: \(f(x) = x^2\), \(g(x) = x^2(x+1)^2\), \(h(x) = x^3 + 3x^2 + 2x\)
The uniqueness lies in the fact that as the constructor, I’m privy to their properties—roots, positive and negative values, and sign variations on different segments. Armed with this knowledge, I can formulate equations that consistently yield true values, adding a layer of complexity:
- \(x^2 \mod{4} > 1\) (always False)
- \(x^2(x+1)^2 \mod{4} = 0\) (always True)
- \(x^3 + 3x^2 + 2x \mod{3} = 0\) (always True)
Yet, for an attacker, deciphering these properties isn’t a walk in the park. This introduces complexity to the code, making it less susceptible to straightforward optimization by compilers (note that \(x\) can be any variable in our code!).
The beauty of opaque predicates lies in their versatility. Once we’ve assembled a robust set of these predicates, we can leverage them to infuse complexity into expressions or introduce what we call “dead code”—segments that are strategically designed never to execute:
if ((var * (var * var + 3 * var + 2)) % 3 == 0) {
// always going to be executed.
} else {
// "dead code", never going to run.
}
This not only enhances the intricacy of the code but also imposes a significant challenge on the attacker: Implementing deobfuscator that can automatically eliminate these expressions is not a trivial task and the dynamic analysis becomes a necessity for them, as understanding the opaque predicates and their impact requires a deeper, real-time examination.
Opaque predicates serve as fundamental building blocks for many obfuscation techniques.
Flattening the CFG
Let’s explore another significant technique commonly employed in code obfuscation: flattening the Control Flow Graph (CFG). The control flow graph serves as a visual representation of code, composed of basic blocks interconnected by edges, which signify branches. Each basic block contains a series of instructions, serving as the fundamental building blocks of code. This structure allows us to quickly identify branches and loops, providing a sequential understanding of the code from start to finish.
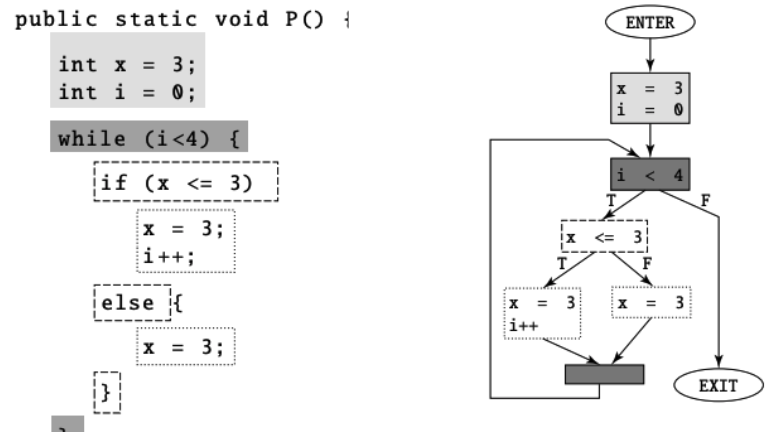
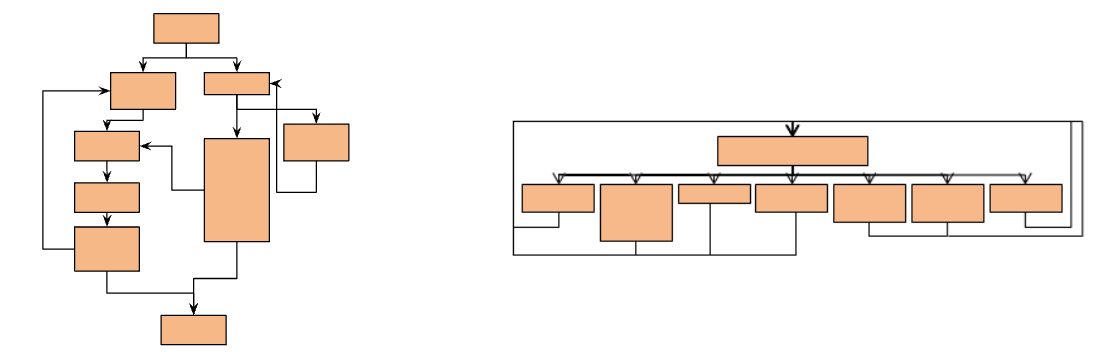
Every static analysis tool, like IDA for instance, offers a visualization of the control flow graph, aiding in code analysis. However, in the realm of obfuscation, we aim to make this structure more opaque. Flattening the control flow graph involves transforming it into a state machine—a daunting task indeed. Initially, we create a state machine representing all possible branches, then proceed to flatten the flow, making it challenging to reverse.
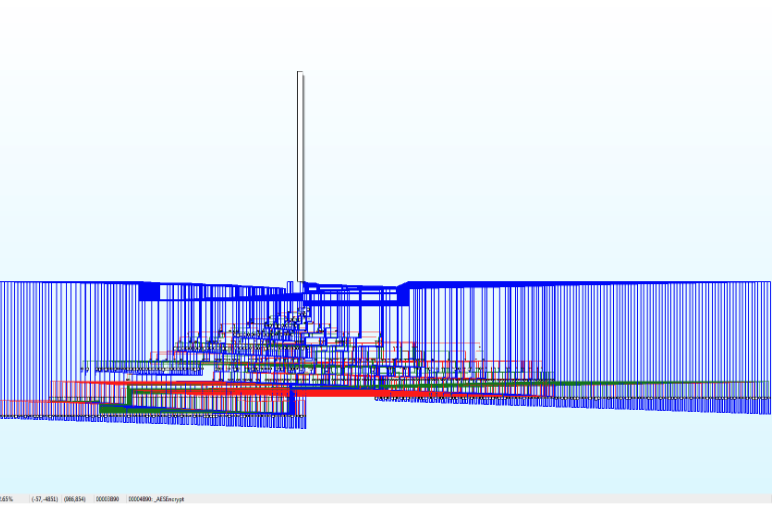
To underscore the impact of obfuscation, let’s consider an example: the AES encrypt algorithm in IDA. Before any obfuscation technique is applied, the control flow graph is discernible, allowing us to detect loops and patterns.

However, after flattening the flow, the same algorithm becomes significantly more complex, highlighting the potency of obfuscation in rendering code more resistant to analysis and tampering.
The Tip Of The Iceberg
The techniques discussed in this blog post are just the tip of the iceberg when it comes to code obfuscation.
There are numerous other methods and strategies, such as virtualization, function merging, function decomposing, strings/constants hiding, and more, that play a crucial role in enhancing software security.
Moreover, the real power lies in the combination of these techniques. However, it’s important to proceed with caution and consider the computational cost of applying multiple techniques together. Additionally, accurately evaluating the security impact of such combinations poses a significant challenge. When multiple obfuscation techniques are combined, the overall effect in terms of security protection is hard to measure, and the computational cost of the combination must be taken into account.
Takeaways
- Although obfuscation is often deemed “weak” because theoretically, it’s always breakable, it remains a practical solution with a significant impact on software security.
- It’s essential to clarify that obfuscation is not about obscurity; it’s about making code harder to understand or modify while retaining functionality.
- Evaluating obfuscation isn’t easy. It’s hard to measure how easy or hard it is to read code, which makes figuring out how effective obfuscation techniques are quite tricky.
Further reading
This entire blog post was based on the book “Surreptitious software: obfuscation, watermarking, and tamperproofing for software protection” by Christian Collberg and Jasvir Nagra.

And also from his article:
Collberg, C.; Thomborson, C.; Low, D. A Taxonomy of Obfuscating Transformations; Department of Computer Science, The Universityof Auckland: Auckland, New Zealand, 1997. https://researchspace.auckland.ac.nz/bitstream/handle/2292/3491/TR148.pdf